
34 例私有病例,能否训练出一个乳腺早筛 AI?
在国家卫健委主办的第二届全国数字健康创新应用大赛中,基于 BUSGen 的方法只使用 34 例私有样本,模型在测试集上取得 AUC 0.947;相比之下,第二名方案使用 1070 例私有样本,AUC 为 0.842。测试集对参赛团队不可见,模型提交至第三方平台完成验证。
这个结果指向医学影像 AI 长期面临的核心问题:当真实病例稀缺、专家标注昂贵、跨机构数据共享受限时,AI 模型是否只能等待更多真实数据?
近日,北京大学智能学院王立威课题组联合北京大学肿瘤医院、北京协和医院、中国医学科学院肿瘤医院、斯坦福大学等单位,在 Nature Biomedical Engineering 发表论文 “A foundation generative model for breast ultrasound image analysis”,提出乳腺超声生成式基础模型 BUSGen。
BUSGen 尝试给出另一条路径:先让生成式基础模型学习乳腺超声图像中的组织结构、病灶形态、设备差异和临床标签之间的关系,再用少量真实样本适配具体任务,生成大规模、带有任务条件的合成数据,最终用这些合成数据训练下游诊断模型。
BUSGen要证明是:
合成数据能否成为医学影像 AI 的有效训练资源。
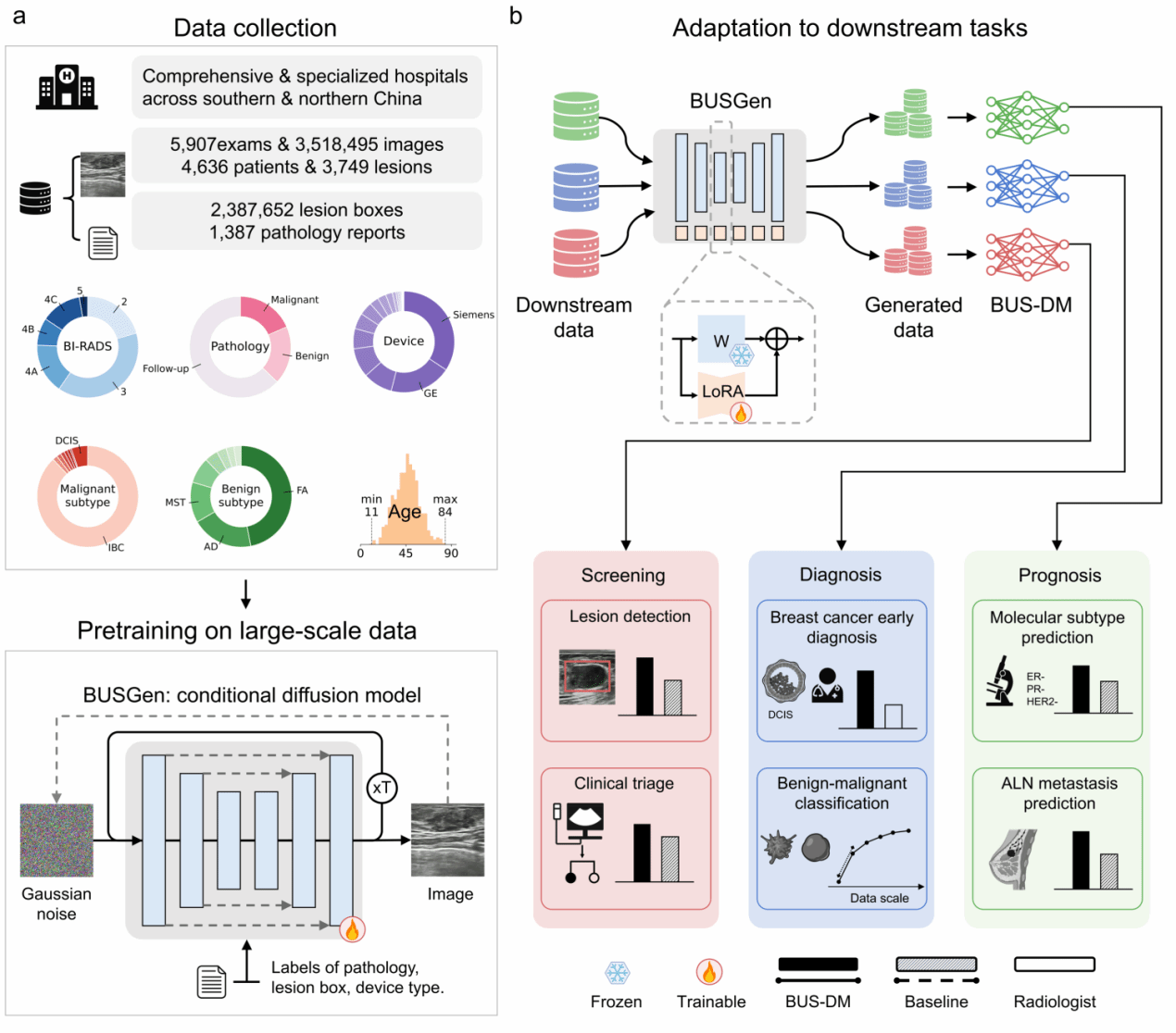
用生成式模型建模乳腺癌语义特征
过去,医学影像 AI 通常遵循一条固定路径:收集真实病例、请专家标注、训练模型、通过更多真实数据提升性能。
但在乳腺超声的场景中,该路径面临多重限制:高质量影像难以大规模获得,罕见或早期病灶样本有限,专家标注成本高,不同医院、设备、医生操作习惯和患者人群之间也存在显著差异。更重要的是,跨机构医学数据共享还受到隐私与合规要求约束。
BUSGen 的核心设计,是把“数据收集问题”转化为“医学影像语义建模问题”。
根据论文和项目介绍,BUSGen 在大量乳腺超声图像上进行预训练,数据覆盖 5907 次检查、4636 名患者和 3749 个病灶。模型在预训练阶段结合病理标签、病灶框、设备类型等条件,学习乳腺超声图像的复杂分布;在下游任务中,则冻结预训练参数,并通过 LoRA 进行小样本适配,生成特定任务所需的大规模合成数据。
这一流程可以概括为四步:
1. 在大规模任务无关乳腺超声数据上训练生成式基础模型;
2. 针对具体任务,用少量真实样本进行适配;
3. 按任务条件可控生成大量合成数据;
4. 使用合成数据训练下游医学AI模型BUS-DM。
这与传统“数据增强”不同。传统增强通常是在已有图像基础上进行旋转、裁剪、扰动或风格变换;BUSGen 则试图学习乳腺超声图像背后的临床语义分布,再按任务需求生成新的训练数据。
医学影像生成的难点不仅像素层面的逼真,真正的关键是病灶边界、组织纹理、声影、设备噪声、病理标签和临床任务之间是否保持一致。只有合成数据具备足够稳定的医学语义,才能用于训练诊断模型。
小样本场景:34 例也能撬动早筛任务
BUSGen 最直接的价值,体现在小样本任务中。
导管原位癌,也就是 DCIS,是乳腺癌早期诊断中的重要类型。由于其超声表现与部分良性病灶相似,医生仅凭超声图像进行准确区分并不容易。对于 AI 模型而言,这类任务同样困难:早期病例数量有限,标注要求高,真实数据积累慢。
在 DCIS 与良性病灶区分任务中,BUS-DM 的 AUC 达到 0.900,高于基线模型的 0.846。在乳腺癌早期诊断相关读者实验中,该方法超过 9 名具备资质的放射科医生的平均表现,并使医生平均敏感性提升 16.5%。
在国家卫健委主办的第二届全国数字健康创新应用大赛中,这种小样本能力进一步得到验证。基于 BUSGen 的方案仅使用 34 例私有样本,就在导管原位癌筛查任务中取得 AUC 0.947,超过使用 1070 例私有样本的第二名方案。
这说明,在有基础生成模型支撑的情况下,少量真实病例不再只是“有限训练集”,而可以成为任务适配的锚点。模型通过少量样本理解目标任务,再生成大量与任务相关的合成训练数据。
百万级合成数据出现 Scaling Effect
BUSGen 更值得关注的结果,是合成数据规模扩大后,下游模型性能持续提升。
过去,合成医学图像常被视为真实数据不足时的补充工具。它能不能真正像真实数据一样推动模型变强,是医学 AI 领域长期存在的疑问。
BUSGen 的实验显示,随着生成数据规模扩大,BUS-DM 的性能持续提升。当合成数据规模扩展到 100 万张时,BUS-DM 在 BUSI 公开测试集上的 AUC 达到 0.929,与使用 288,767 张真实数据训练的 NYU-AI 强基线表现接近。
这意味着,合成数据的价值不只是“增加样本数量”,而在于是否承载了足够有效、可迁移的医学影像语义。
在 BUSGen 中,合成数据开始呈现出类似真实数据的 Scaling Effect:数据规模越大,下游模型越强。这也是生成式基础模型区别于普通图像生成器的重要标志。
合成数据过去是补充项;在 BUSGen 中,它开始成为训练高性能医学 AI 的主体数据资源之一。

仅用合成数据训练,为什么反而可能更泛化?
BUSGen 还有一个反直觉发现:在部分下游任务中,仅使用合成数据训练的模型,泛化性反而优于直接使用真实数据训练的模型。
原因在于,真实临床数据并不天然“干净”。
在真实医院环境中,数据采集过程可能包含大量隐藏偏差。例如,经验丰富的医生可能更多接诊高风险患者,而这些患者又可能更集中使用某一类设备检查。模型如果直接从真实数据中学习,可能会把医生分诊习惯、设备差异、采集条件误认为疾病特征。
这就是医学 AI 中常见的虚假相关问题。
BUSGen 的生成式语义建模和可控采样流程,可以在一定程度上削弱这些采集偏差,使下游模型更聚焦于病灶本身的影像语义,而不是学习真实数据中偶然存在的捷径。
这也解释了为什么 BUSGen 的意义不只是“生成更多图像”。它更重要的能力,是通过生成过程重组数据分布,让模型学习更接近临床任务本质的医学语义。像真实临床分布,但不复制真实患者
合成数据能否用于医学 AI 训练,还必须回答两个问题:
第一,生成图像是否足够真实?
第二,生成图像是否只是复制训练集中的患者图像?
在真实性方面,研究团队进行了视觉图灵测试。6 名放射科医生被要求区分真实图像和 BUSGen 生成图像,结果显示真实与合成数据的可区分性接近随机水平。项目页面披露,测试中真实/合成图像的可区分范围约为 0.42 到 0.59,说明医生难以稳定地区分两类图像。
在隐私保护方面,研究团队比较了生成样本与训练集中最近邻图像在特征空间和结构相似性上的差异。结果显示,BUSGen 生成的数据并不是对真实训练图像的简单复刻。
这为医学数据共享提供了新的技术路径:合成数据可以保留真实临床分布中的有效语义,同时降低直接暴露真实患者数据的风险。

从筛查到诊断和预后,合成数据训练模型跨任务验证
在多个下游任务中,仅使用 BUSGen 生成数据训练的 BUS-DM 均表现出较强性能。
在病灶检测任务中,BUS-DM 在小病灶检测上的 AP 达到 0.702,高于基线模型的 0.657;在整体病灶检测上,BUS-DM 的 AP 达到 0.934,高于基线模型的 0.912。
在机会性筛查相关的良恶性分类任务中,BUS-DM 的 AUC 达到 0.918,高于基线模型的 0.870。
在良恶性鉴别任务中,BUS-DM 在内部测试集和外部测试集上的 AUC 分别达到 0.953 和 0.951,均高于对应基线模型。
在预后相关任务中,BUS-DM 在三阴性乳腺癌分子分型预测中的 AUC 为 0.803,在腋窝淋巴结转移状态预测中的 AUC 为 0.895,也均优于基线模型。
这些结果表明,BUSGen 并不只适用于某一个单点任务,而是可以通过小样本适配和合成数据生成,覆盖筛查、诊断、分型和预后等多个乳腺超声 AI 场景。
医学影像 AI 的训练数据,正在进入新阶段
从研究路径看,BUSGen 的意义不只是“生成更像真的乳腺超声图像”。
更重要的是,它展示了一种新的医学 AI 开发方式:真实数据不再只是被动收集的样本库,也可以成为训练生成式基础模型、适配临床任务、构造合成训练数据的基础资源。
这并不意味着真实数据不再重要。BUSGen 仍然依赖真实数据完成预训练、小样本适配和临床验证。真正的变化在于,真实数据的角色发生了转变:
从直接训练所有下游模型,转向训练一个能够持续生成任务数据的基础模型。
对于科研而言,这为罕见病、早期病灶和难标注任务提供了新的数据解决方案。
对于临床而言,它有助于降低模型开发对大规模私有数据的依赖,提升模型在不同设备、医院和患者人群中的泛化能力。
对于数据治理而言,合成数据也为隐私保护和安全共享提供了新的技术路线。
据团队介绍,相关方法已在国家级数字健康创新应用比赛中获得验证,并被企业应用于乳腺超声 AI 产品研发和落地场景。
医学影像 AI 的数据瓶颈,不可能只靠收集更多病例解决。BUSGen 展示了一种新的可能:让生成式人工智能学习医学影像的底层分布,再把这种能力转化为可训练、可验证、可应用的数据资源。
当医学影像数据可以被高质量生成,AI 模型训练的边界也将随之改变。


